
This page highlights recent AI-enabled research systems and prediction workflows that connect clinical questions, EHR data engineering, LLM experimentation, and manuscript development. Across these projects, I have been using Codex and Claude not only for coding assistance, but also for planning, prompt iteration, pipeline design, validation, and research writing support.
Clinical Summarization Platform
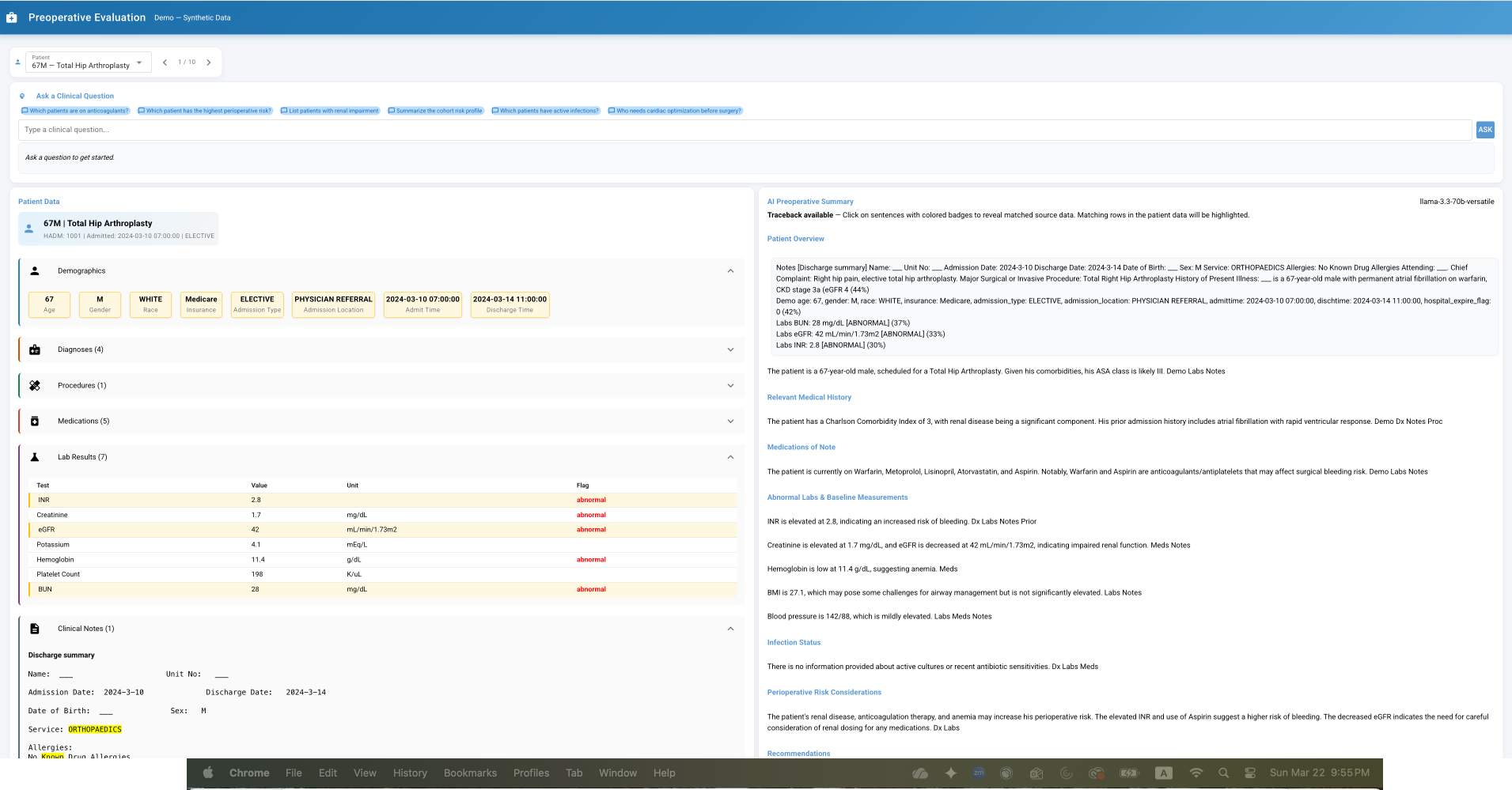
PreoperativeEvaluation
An end-to-end research platform for generating anesthesiology-style preoperative evaluation summaries from longitudinal EHR data in MIMIC-IV.
What the system does
The workflow combines BigQuery-based cohort construction, structured clinical data extraction, open-source LLM summarization, and rubric-based evaluation into a coordinated multi-agent research pipeline.
Why it matters
Preoperative assessment often requires clinicians to integrate fragmented prior admissions, medications, labs, microbiology, and comorbidity history. This project explores how AI can make that synthesis more systematic, auditable, and clinically useful, with special emphasis on making each summary traceable back to the underlying patient record.
Key capability
The demo supports trace-back highlighting so users can inspect the raw patient data corresponding to specific portions of the generated summary, making the system more transparent and easier to evaluate clinically.
Highlights
- Built a LangGraph-style multi-agent pipeline spanning data retrieval, summarization, evaluation, and analysis.
- Integrated perioperative context including medications, labs, microbiology, comorbidity burden, baseline measurements, and prior admissions.
- Benchmarked open-source LLMs across multiple inference backends and evaluated summary quality with rubric-based commercial LLM judges.
- Developed supporting research artifacts including experiment outputs, publication figures, manuscript drafts, a clinician review app, and a synthetic demo.
- Published an interactive demo for exploring the preoperative summary workflow in a shareable web interface.
- Used Codex and Claude for prompt design, rubric iteration, experiment planning, implementation support, and manuscript development.
Technical focus: Python, LangGraph/LangChain-style orchestration, BigQuery/GCP, Hugging Face and vLLM model serving, commercial LLM-based evaluation, and reproducible research-tooling pipelines for figures, tables, and exports.
Prediction and Fine-Tuning Workflow
PostoperationPrediction
A preoperative prediction workflow for postoperative infection using longitudinal EHR context and instruction-style LLM classifiers.
What the workflow does
The project builds a leakage-aware surgical cohort, creates modeling-ready representations from preoperative and prior-admission data, and evaluates open-weight LLMs for clinically meaningful infection outcomes.
What we learned early
Reduced-context strategies performed better than naive long-context truncation in pilot evaluation, improving held-out ROC AUC from 0.675 to 0.883 and average precision from 0.159 to 0.478.
Highlights
- Framed the first manuscript around ICD-based postoperative infection as a clinically coherent primary endpoint.
- Built patient-level cohorting and split logic to reduce leakage from repeat admissions.
- Constructed modeling inputs that combine demographics, procedures, comorbidity context, medications, labs, microbiology, and prior-admission note history.
- Prepared fine-tuning and evaluation pipelines for instruction-style LoRA and QLoRA workflows.
- Used a planning-oriented multi-agent workflow, supported by Codex and Claude, to coordinate data, modeling, validation, and manuscript tasks.
Technical focus: longitudinal EHR representation, patient-level dataset design, fine-tuning exports for instruction-style models, and evaluation pipelines for clinically grounded binary prediction tasks.
AI Research Workflow
Planning
Codex and Claude as research collaborators
I increasingly use agentic workflows to break large clinical AI projects into planning, coding, evaluation, and writing threads that can move in parallel.
Validation
Reproducibility stays central
The goal is not to replace methodological rigor, but to accelerate careful cohort design, prompt iteration, result checking, and manuscript preparation.
Direction
AI as part of the full research stack
These projects reflect a broader agenda of treating AI as one component in clinically grounded, end-to-end research systems rather than as an isolated modeling layer.